
又是藤校生辍学创业,开拓技术新路线,挑战主流的故事。
两个从哈佛退学的00后本科生,开发了一款新的AI芯片,筹集了高达1.2亿美元。

图源:X(
两位辍学生创立的公司名为Etched AI,开发的这款芯片名为「Sohu」(但不是"搜狐"),是专为Transoformer架构大模型研发的ASIC芯片。相比于占据AI芯片垄断地位的、原本作为图形处理器的英伟达GPU,Sohu芯片只运行Transformer架构的模型,但运行速度比GPU快一个数量级。
图源:X(
当地时间6月25日,Etched宣布完成 1.2 亿美元的 A 轮融资,由早期投资机构Primary Venture Partners 和 Positive Sum Ventures 共同领投。重量级天使投资人包括风险投资家 Peter Thiel、GitHub 首席执行官 Thomas Dohmke、自动驾驶公司 Cruise 的联合创始人 Kyle Vogt, 以及Quora的联合创始人Charlie Cheever。目前公司没有透露新一轮融资后的估值。已经有早期客户,向Etched AI预订了数千万美元的硬件订单。
Etched AI 位于加利福尼亚,是一家"两人公司",两位创始人都是2020年进入哈佛,在校时疯狂兼职打工,后来休学创业,其中一位是21岁华裔小哥Chris Zhu,一位是Gavin Uberti。
英伟达的AI芯片帝国,不乏挑战者:芯片初创公司Cerebras Systems的大体积单个芯片,以及 Tenstorrent公司的RISC-V技术芯片。现在英伟达又多了一个更年轻、更雄心勃勃的对手--Etched AI。
如何比H100更快20倍?
众所周知,AI芯片的巨头英伟达采取的GPU原本是图形处理器,擅长并行处理多个简单的计算,后用于训练AI模型,因为训练AI需要同时对所有数据样本执行相同的操作。
但训练AI大模型需要更专用的芯片。Etched首席执行官Uberti 在公开采访中说,"人工智能的发展已经到了这样一个阶段,性能优于通用 GPU 的专用芯片是不可避免的--全世界的技术决策者都知道这一点。"
「Sohu」芯片是一种 ASIC(专用集成电路),一种为特定应用量身定制的芯片。Sohu只运行Transformer架构的模型。Transformer 是由谷歌研究人员团队于 2017 年提出的,已成为占主导地位的生成式 AI 模型算法。
Etched 称Sohu芯片采用台积电 4 纳米制程制造,可以提供比 GPU 更好的推理性能,同时消耗更少的能源。
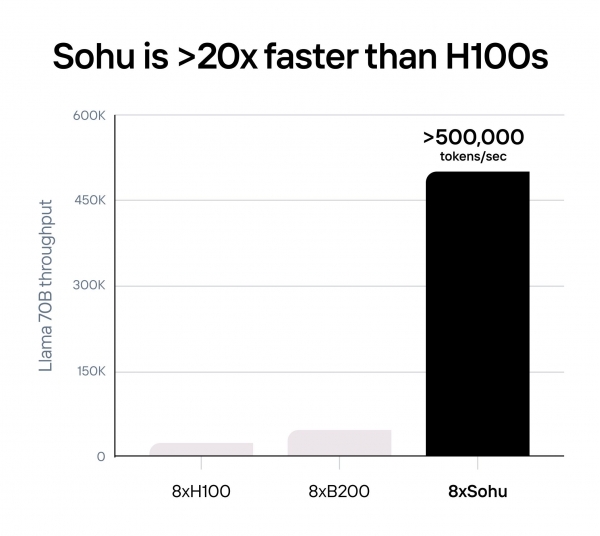
Etched宣称,与H100相比,一台集成了8块Sohu芯片的服务器,能匹敌160块H100芯片,这意味着Sohu芯片的速度比H100快20倍。与英伟达下一代 Blackwell (B200) GPU相比,Sohu芯片快 10 倍以上,而且更便宜。
针对Llama 70B 开源大模型,一台Sohu芯片每秒运行超过 50万个token,比 H100 芯片(2.3万token/秒)多 20 倍,比 B200 芯片(约 4.5万token/秒)多 10 倍。
针对 Llama 3 70B 的 FP8 精度基准测试显示:无稀疏性、8 倍模型并行、2048 输入或 128 输出长度。
Sohu的推理速度是如何做到这么快的?
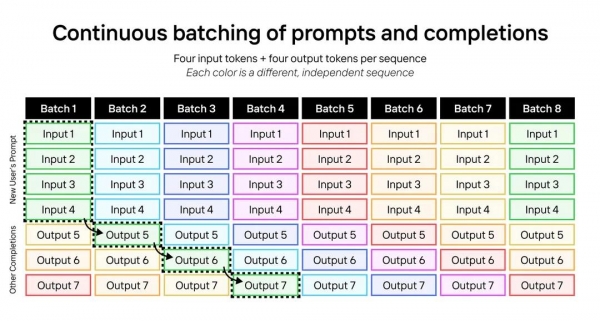
连续批处理提示和补全:每个序列包含四个输入标记和四个输出标记;每种颜色代表一个不同的、独立的序列。图源:Etched官网
Sohu芯片采用了一种名为"连续批处理"(Continuous batching of prompts and completions)的创新技术。这种方法巧妙地将多个输入和输出序列组合在一起处理,充分利用了芯片的计算资源。
想象一下,就像是在一个大厨房里,多个厨师同时使用相同的食材(模型权重)烹饪不同的菜肴(处理不同的输入序列)。
这种技术的优势在处理长输入短输出的场景中尤为明显,这恰好符合大多数AI应用的使用模式。通过这种方式,Sohu芯片能够在处理Llama-3-70B等大型模型时达到惊人的效率,远超传统GPU的表现。
简单来说,Sohu芯片就像是一个超级高效的并行处理器,能够同时处理大量的AI任务,而不会被内存读取速度拖后腿。这一突破性的技术有望大大提升AI应用的响应速度和处理能力,为用户带来更流畅、更智能的体验。
此外,Sohu还能做到简化推理所用的硬件和软件。由于Sohu不运行非Transformer模型,Etched 团队可以去掉与Transformer无关的硬件,并削减传统上用于部署和运行非Transformer的软件开销。
相比之下,英伟达的GPU中,并不是所有晶体管都用于大模型的张量计算。例如,H100 有 800 亿个晶体管,但只有27 亿个专用于张量核心的晶体管,这意味着 H100 GPU 上只有 3.3% 的晶体管用于大模型的矩阵乘法。
Sohu芯片通过仅运行变压器,在芯片上安装更多的 FLOPS,而无需诉诸较低的精度或稀疏性。
图源:X(
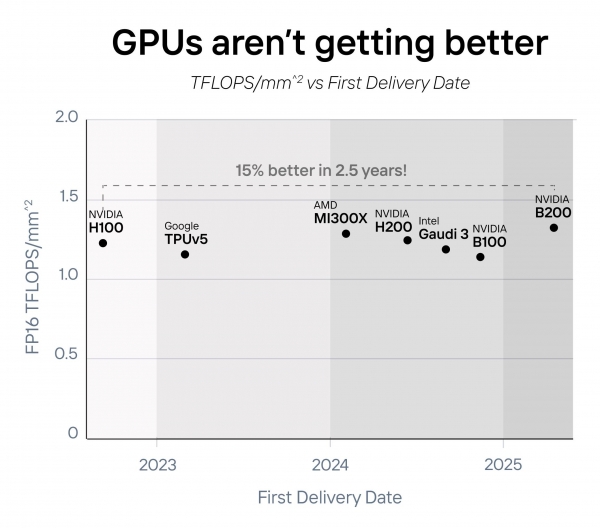
GPU 并没有在单芯性能上变得更好,只是变得更大了。在过去四年中,计算密度 (TFLOPS/mm^2) 仅提高了约 15%。
新一代GPU都是靠堆叠多张卡来提升算力--将两个芯片算作一张卡,以"翻倍"其性能。NVIDIA B200、AMD MI300X、Intel Gaudi 3、AWS Trainium2等都是如此。
随着摩尔定律(CPU的集成电路上可容纳的晶体管数目,约每隔两年便会增加一倍)放缓,提高芯片性能的唯一方法是采取专业化的芯片,而非通用芯片。

图源:Etched官网
GPU触达天花板:英伟达、AMD、英特尔、亚马逊等公司都通过将两块芯片合为一体来成倍增强性能。2022年至2025年间,AI芯片技术并没有"变好",而只是"变大"。这期间所有的芯片性能提升都是通过"变大"实现的,除了Etched。
Etched宣称,如今AI 模型的训练成本超过 10 亿美元,将用于 100 亿美元以上的推理。对于这么大的需求,用 5000 万至 1 亿美元的定制芯片来换取1%的性能改进,是合理的。
如果 AI 模型一夜之间速度提高 20 倍、成本降低 20 倍,会发生什么?
当下,Gemini 要花超过 60 秒的时间来回答有关视频的问题,用AI运行代码,需要数小时才能完成任务,成本比雇佣人类码农更高。视频生成模型,一秒钟才能生成一帧画面。当 ChatGPT 注册用户达到 1000 万(这还只是全球用户的 0.15%)时,甚至 OpenAI 也出现GPU算力荒。
即使以多卡互联的方式堆叠显卡,以每两年 2.5 倍的速度不断制造更大的 GPU,也需要十年的时间才能实现即时的视频生成。
而当Sohu芯片能让大模型的推理速度提高20倍,视频模型生成画面能更即时、迅速,
消息一出,网友们大多表示欢迎,认为这家公司的出现将加速AI创新:
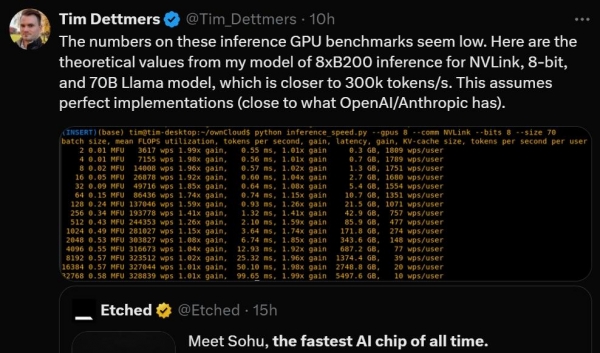
这些推理 GPU 基准测试中的数字很低。下面是我的8xB200推理模型的理论值,适用于 NVLink,8位和70B Llama模型,后者更接近300k token/秒。这意味着完美的实现(接近OpenAl/Anthropic所拥有的)。图源:X(@Tim_Dettmers)
这使得使用LLM的高级推理用例更加可行。他们网站上有很多例子。这将加速创新,AI将为更好的AI的发展做出更大的贡献。未来正以极快的速度到来。图源:X(@leonovco)
Sohu用户"直接烧进硅里" vs "GPU呆子"抱怨在不损失通用计算能力的情况下,无法在Transformer模型上达到40%以上的利用率。此图暗示了SoHu芯片在AI特定任务上的优势,以及传统GPU在处理新型AI模型时可能面临的效率瓶颈。图源:X(@qamcintyre)
两位哈佛本科生休学创业的生死赌注
Gavin Uberti和Chris Zhu休学创业,是在2022年10月,那时离Chat-GPT问世还有一个月,Transformer还远没有成为主流地位的架构--图像和视频生成模型使用的是U-Net,自动驾驶汽车模型使用CNN。但在那时,两位创业者已经把全部赌注下在Transformer专用芯片上。
"我们在人工智能领域下了最大的赌注,"Etched联合创始人Gavin Uberti在一次公开采访中表示, "如果Transformer消失了,我们就会死。但如果Transformer能坚持下去,我们就是有史以来最大的公司。"
"后来当 ChatGPT 推出时,英伟达股票卖爆了,特别是当其他发布的所有模型也都是Transformer架构时,我们发现自己在正确的时间处于正确的位置。"Gavin说。
"我们对自己正在做的事情感到如此兴奋,为什么我们辍学,我们说服了这么多人离开这些芯片项目--这是我们要做的最重要的事情。"后来加入Etched的联合创始人Robert Wachen说。
让我们看看几位如此年轻的创业者的背景是怎样的:
Gavin Uberti
Gavin Uberti 是Etched的联合创始人兼首席执行官,创业前就读于哈佛大学,攻读数学学士和计算机科学硕士学位。

图源:semi
Gavin原本计划离开哈佛休学一年,但最终在 OctoML 找到了一份从事 ApacheTVM (深度学习编译器框架)开源编译器和matmul内核的工作。
在为 Arm Cortex M4 和 Cortex M7 内核开发微内核时,Gavin 注意到 Arm 的指令集没有 8 位 MAC SIMD 指令,只有 16 位(M4 和 M7 支持许多其他 8 位 SIMD 操作,但 Helium 引入了 8 位 MAC SIMD 指令)。这意味着 8 位 MAC SIMD 操作实际上仅以一半的速度运行。这可以说是Gavin创办Etched的一个关键因素。
"这个问题永远无法解决,每次上班,我都必须处理这个疏忽,这让我和 Chris 一起思考,我们必须能够做得更好,"Gavin说。
与此同时,Gavin和Kris还看到语言模型领域正在发生变化,也就是人们对基于Transformer 架构的 LLM 的兴趣激增。
他和Zhu决定创办一家芯片公司,为 LLM 设计更高效的推理架构。虽然目前市场上还没有专门针对 LLM 的加速器,但 Nvidia 已经宣布了针对转换器的软件功能,其他加速器公司也宣布支持语言和视觉转换器。Etched.ai 计划通过进一步专业化来与现有企业竞争。
"你无法通过泛化获得我们所获得的那种改进,"Gavin说。"你必须在单一架构上下大赌注,不仅仅是人工智能,还要在更具体的东西上下赌注……我们认为 Nvidia 最终会做到这一点。我们认为这个机会太大了,不容忽视。"
图源:LinkedIn
在Etched,他正在为Transformer架构构建 ASIC(Application-Specific Integrated Circuit,专用集成电路,为特定用途而设计的定制化芯片,能在特定任务上实现最佳性能和效率),与通用 AI ASIC 相比,其吞吐量高出一个数量级。

图源:Bloomberg,采访视频链接:
https://x.com/Etched/status/1805775989500428739
Chris Zhu

图源:X(@czhu1729)
Chris Zhu,Etched.ai 的联合创始人,目前正在开发下一代 LLM 加速器系统。
在创业前,他在校期间就不断参加科研,不断兼职实习。
他于2021年9月至2022年4月,在哈佛大学担任各类计算机科学课程的教学研究员,同时期还曾在亚马逊和 AvantStay 担任软件工程师实习,分别专注于后端物联网基础设施和 AWS 全球收入运营。
Chris的早期履历还包括:在2021年2月至6月于哈佛本科资本合伙公司担任实习分析师;2018年1月至2020年5月在麻省理工学院担任研究员;2019年6月至8月担任波士顿大学 PROMYS 的初级辅导员。
Robert Wachen

图源:X(@robertwachen)
Robert Wachen是Etched的联合创始人和COO,他有着非常丰富的创业经历。
他的学术和创业经历包括:哈佛大学咨询集团、哈佛肯尼迪学院行为洞察小组代表、Prod联合创始人(2022年7月至今)、Mentor Labs联合创始人兼CEO(2022年1月至今)Generate Sales Online 创始人(2016年12月至今)、Birthday Cakes 4 Free Maryland 联合创始人兼总裁(2015年9月至今)、蒙哥马利县地区 SGA 财务主管以及蒙哥马利县公立学校"Early Edge"职业准备计划的学生代表。
英伟达目前是AI芯片的巨头。据TechCrunch估计,英伟达占据了人工智能芯片约 70% 至 95% 的市场份额。Etched AI的Transformer专用芯片是英伟达的一个年轻竞争者。
挑战英伟达的年轻竞争对手还有很多。一个对手是Cerebras Systems公司,正在开发由整块晶圆做成的、单个体积最大的 AI 芯片,已累计融资7.2亿美元,背后有OpenAI的首席执行官Sam Altman投资。6月20日The Information称Cerebras已经秘密申请上市。
另一个英伟达挑战者是Tenstorrent,该公司正在使用一种名为 RISC-V 的流行技术来开发AI 芯片。
英伟达鼎立山头,新势力群雄环伺,两位00后哈佛辍学生创立的Etched AI或许成为下一个英伟达挑战者。