【文/观察者网 陈思佳】近期,中国人工智能公司深度求索(DeepSeek)发布的DeepSeek-R1模型轰动全球,使用极低的成本实现了匹敌美国顶级AI模型的效果,得到从业者的广泛称赞。许多研究人员、投资者和西方媒体感叹,中国AI模型令硅谷震惊,甚至可能改变大模型的研发规则。
随着DeepSeek爆火,其创始人梁文锋也受到公众关注。作为一位17岁考入浙江大学、在量化投资和AI领域均取得惊人成就的"学霸",梁文锋却始终保持低调,很少抛头露面。许多人好奇,这位低调的85后创业者究竟是如何取得成功。
用数学和AI进行量化投资
公开资料显示,梁文锋1985年出生于广东省湛江市。2002年,17岁的梁文锋考入浙江大学电子信息工程专业,并在2010年获得信息与通信工程硕士学位。
在校期间,他对金融市场产生了浓厚兴趣。特别是在2008年全球金融危机爆发后,他曾带领团队使用机器学习技术分析市场数据,尝试实现全自动量化交易。这一经历为梁文锋积累了实践经验,也为他日后的职业生涯奠定了坚实的基础。

DeepSeek创始人梁文锋
毕业后,梁文锋首先进入了金融领域。2013年,他与浙大同学徐进共同创立了杭州雅克比投资管理有限公司,并在2015年成立了杭州幻方科技有限公司,致力于通过数学和AI进行量化投资。
2016年,幻方量化推出首个基于深度学习的交易模型,并开始将GPU引入计算交易仓位。在此之后,梁文锋不断扩大AI算法研究团队,将AI技术深度融入量化策略,逐步取代传统模型。2017年,幻方宣称实现投资策略全面AI化。2018年,幻方正式确立以AI为核心的发展战略。
但随着业务的快速扩展,计算资源不足的问题逐渐显现。2019年,梁文锋带领团队自主研发了"萤火一号"训练平台。2020年开始,总投资近2亿元、搭载了1100张GPU的"萤火一号"正式投入运作。2021年,幻方投入10亿元建设"萤火二号"。
幻方量化在2018年首次获得私募金牛奖,这是中国私募证券领域的最高奖项。2019年,梁文锋在当年的金牛奖颁奖仪式上发表了主题演讲《一名程序员眼里中国量化投资的未来》,这是他少有的公开发言。
当时,梁文锋在演讲中表示,"量化投资的未来,是用技术让市场更有效率"。
在AI领域一鸣惊人
2023年,梁文锋宣布正式进军通用人工智能(AGI)领域,创办了深度求索(DeepSeek)。据报道,DeepSeek包括创始人梁文锋在内,仅有139名工程师和研究人员。相比之下,开发ChatGPT的OpenAI有1200名研究人员,开发Claude模型的Anthropic则有500多名研究人员。
虽然团队规模不大,DeepSeek在此后一年多里取得了令人瞩目的成果。2024年5月,DeepSeek发布DeepSeek-V2模型,凭借创新的模型架构和性价比引发关注。DeepSeek-V2的API定价为每百万tokens输入1元、输出2元,价格仅为美国OpenAI GPT-4 Turbo的百分之一。
DeepSeek解释称,DeepSeek-V2采用了创新的架构,例如注意力机制方面的MLA(多头潜在注意力)和前馈网络方面的DeepSeekMoE架构等,以实现具有更高经济性的训练效果和更高效的推理。
据澎湃新闻报道,DeepSeek-V2的出现一度引发国内的大模型"价格战",百度、阿里、字节跳动等大厂纷纷宣布大模型产品降价。对此,梁文锋在接受媒体采访时表示,DeepSeek无意成为行业鲇鱼,低价背后是希望算力普惠。
去年12月26日,DeepSeek-V3模型发布,引发科技行业高度关注。DeepSeek网站发布的信息显示,DeepSeek-V3多项评测成绩超越了Qwen2.5-72B和Llama-3.1-405B等其他开源模型,甚至可以与GPT-4o、Claude 3.5-Sonnet等顶级闭源模型一较高下。
更引人注目的是,DeepSeek-V3使用的成本和算力极低,仅使用2048颗算力稍弱的英伟达H800 GPU,成本约为557.6万美元。相比之下,OpenAI的GPT-4o训练成本高达7800万美元。这意味着,DeepSeek-V3以十分之一的成本实现了足以与GPT-4o较量的水平。
今年1月20日,DeepSeek进一步取得突破,正式发布DeepSeek-R1模型。该模型在数学、代码、自然语言推理等任务上,性能比肩OpenAI o1正式版。该模型在后训练阶段大规模使用强化学习(RL)技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。
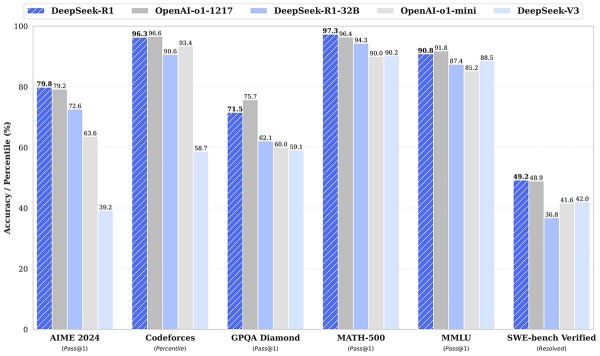
DeepSeek-R1、OpenAI-o1-1217和DeepSeek-V3的性能比较 DeepSeek微信公众号
这一系列成就震动全球科技行业。美国OpenAI创始成员之一安德烈·卡帕西(Andrej Karpathy)在社交媒体上称赞:"DeepSeek在有限资源下展现了惊人的工程能力,它可能重新定义大模型研发的规则。"
硅谷知名风险投资家马克·安德森(Marc Andreessen)将DeepSeek-R1的发布与美国总统特朗普入主白宫相提并论,他称赞这是"最令人惊叹的突破之一,给世界的一份意义深远的礼物"。
DeepSeek的成功与梁文锋在团队管理和技术研发上的独特策略有着密切的关系。他组建了一支由本土年轻程序员组成的团队,不依赖海归或高级技术专家,团队成员多为应届毕业生或工作经验不超过5年的年轻人。
梁文锋曾向媒体坦言,团队"并没有什么高深莫测的奇才,都是一些Top高校的应届毕业生、没毕业的博四、博五实习生,还有一些毕业才几年的年轻人"。他认为,"创新需要摆脱惯性,经验有时会成为包袱。"
低调的"技术理想主义者"
从应用AI进行量化投资,到投身AI大模型研发,驱动梁文锋的却并不是来自商业方面的理由。他在有限的几次媒体采访中坦言:"幻方的主要班底里,很多人是做人工智能的。当时我们尝试了很多场景,最终切入了足够复杂的金融,而通用人工智能可能是下一个最难的事之一,所以对我们来说,这是一个怎么做的问题,而不是为什么做的问题……如果一定要找一个商业上的理由,它可能是找不到的,因为划不来。"
他表示,"很多人会以为这里边有一个不为人知的商业逻辑,但其实,主要是好奇心驱动……对AI能力边界的好奇。"
DeepSeek一直坚持开源路线,主动向全球开发者分享了核心技术成果。在一些业内人士看来,梁文锋其实是一位低调的"技术理想主义者"。
去年,梁文锋在接受媒体采访时表示,在颠覆性的技术面前,闭源形成的护城河是短暂的。即使OpenAI闭源,也无法阻止被别人赶超。"开源更像一个文化行为,而非商业行为。给予其实是一种额外的荣誉。一个公司这么做也会有文化的吸引力。"
梁文锋认为,随着经济发展,中国也要成为贡献者:"我们已经习惯摩尔定律从天而降,躺在家里18个月就会出来更好的硬件和软件。Scaling Law(缩放定律)也在被如此对待。但其实,这是西方主导的技术社区一代代孜孜不倦创造出来的,只因为之前我们没有参与这个过程,以至于忽视了它的存在。"
他当时还表示,中国AI不可能永远处在跟随的位置,"很多国产芯片发展不起来,也是因为缺乏配套的技术社区,只有第二手消息,所以中国必然需要有人站到技术的前沿。"