国内大模型企业的十万卡时代,真的要来了吗?
9月25日,百度发布了全面升级的百舸AI异构计算平台4.0,百度智能云事业群总裁沈抖直言,百舸4.0就是部署十万卡大规模集群而设计的。

百度集团执行副总裁、百度智能云事业群总裁沈抖观察者网
而就在几天前,阿里云宣布其灵骏单网络集群已拓展至10万卡级别。此前,腾讯也发布了支持十万卡集群的星脉网络2.0。
一度还停留在设想层面的十万卡集群,突然成为舆论焦点是在9月初。马斯克突然宣布在短短122天内建成10万张英伟达H100显卡的Colossus集群,意味着其算力可能已经超过OpenAI。
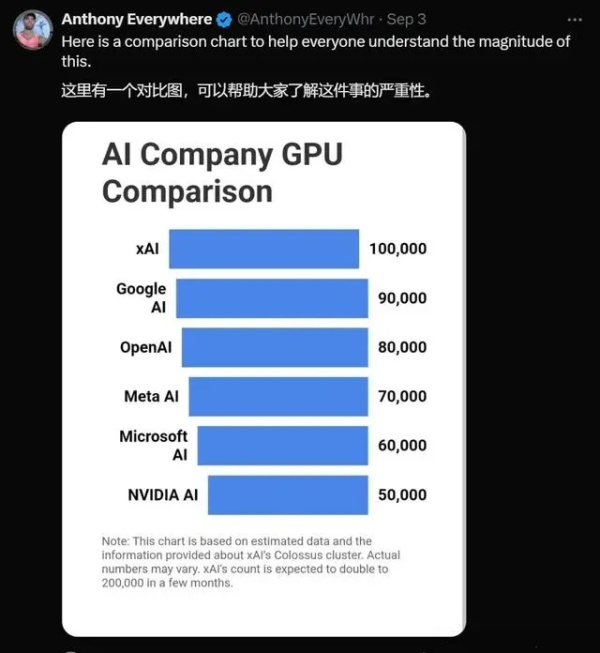
由显卡规模撑起的算力水平,是决定大模型性能的最重要指标之一。一般认为,1万枚英伟达A100芯片,是做好AI大模型的算力门槛。
建一个万卡集群,单是GPU的采购成本就高达几十亿,因此国内能够部署万卡规模集群的,原本就只有阿里、百度等寥寥几家大厂。而想要部署十万卡集群,其"烧钱"程度可想而知。
除了资金成本,十万卡集群同样面临巨大的技术挑战。沈抖指出,GPU是一种很敏感的硬件,连一天之内气温的波动,都会影响到GPU的故障率,而且规模越大,出故障的概率就越高。"Meta训练llama3的时候,用了1.6万张GPU卡的集群,平均每3小时就会出一次故障。"
此外,区别于传统CPU集群的串行特点,大模型训练过程需要全部显卡同时参与并行计算,对网络传输能力也提出了更大的挑战。
相比于美国同行,中国大模型企业还面临一重特殊的困难,无法像马斯克那样全部采用英伟达方案,而是需要使用包括国产GPU在内的异构芯片。这也意味着,即使同样十万张显卡,国内企业在算力规模上也很难同美国企业匹敌。
在上述三重挑战之下,国内大模型企业的进步速度也有目共睹。
据沈抖介绍,百舸4.0在万卡集群上实现了有效训练时长占比99.5%以上,业界领先,并通过在集群设计、任务调度、并行策略、显存优化等一系列创新,大幅提升了集群的模型训练效率,整体性能相比业界平均水平提升高达30%。
而阿里云CTO周靖人此前也透露,目前阿里云的万卡算力集群可以实现大于99%以上连续训练有效时长,模型算力利用率可提升20%以上。
但随着性能提升,大模型成本问题只会越来越引人注目。单从能耗来看,沈抖透露,十万卡集群每天就要消耗大约300万千瓦时的电力,相当于北京市东城区一天的居民用电量。
一位开发者向观察者网直言,尽管在过去一年中大模型厂商的降价幅度确实可观,但这更多是平台补贴开发者的结果,并非根本解决之道。
对此,阿里云方面强调,AI发展仍然处在一个非常早期的阶段,必须要靠降价带动应用爆发,而阿里云搞AI大基建,并不会只算眼前账。
本文系观察者网独家稿件,未经授权,不得转载。