
中国人工智能公司深度求索(DeepSeek)在大模型上取得的成功,目前已经深深撼动了硅谷同行们的信心。
1月23日,在美国匿名职场论坛TeamBlind上,一名Meta公司员工发布涉深度求索的帖子"Meta生成式人工智能部门陷入恐慌",引起广泛讨论。该员工在文中称,从深度求索发布DeepSeek-V3开始,就已经让Meta的Llama 4在各项测试中处于落后,"更糟糕的是,这家不知名中国公司仅为此花费了550万美元。"
550万美元是什么概念呢?"Meta生成式AI部门里的每位'领导'的薪资都超过了这个数字",该Meta员工称,"而我们却有几十位这样的领导,我根本无法想象该如何向公司高层证明部门目前高额成本的合理性。"
该员工透露,目前Meta的工程师们正在疯狂研究分析DeepSeek的成功,并试图从中复制任何能复制到的东西,这不是夸张。"然而,当DeepSeek-V1发布时,事情变得更加可怕了",该员工表示虽然不能透露太具体,但有些事情很快将会公开。

1月20日,深度求索发布DeepSeek-R1开源大模型,对标OpenAI o1正式版。南华早报
最后,该员工反思称,Meta的生成式AI部门本应该是一个以工程为重点的小型组织,但因为很多人都想进来分一杯羹,人为膨胀了组织的规模,到最后人人都是输家。
目前不清楚该员工所指具体为何,是否暗示该公司生成式AI部门面临的调整或者其他情况的可能性,这还需要进一步观察,不过Meta在大模型中竞争中脚步放缓已是事实。
公开信息显示,帖子中提及的DeepSeek-V3于去年12月26日对外发布,该模型一经发布就站上了开源模型No.1的位置。根据当时深度求索公布的技术报告数据,Meta公司的Llama 3.1-405B仅在大规模多任务理解数据集MMLU-Pro一项,接近DeepSeek-V3水平,其余多项几乎都不及八成,甚至在算法类代码场景和工程类代码场景下,Llama 3.1-405B只有DeepSeek-V3的一半水平。

而4天前(1月20日),深度求索对外正式发布DeepSeek-V1,官方技术报告的测试所对照模型中,仅有OpenAI公司闭源的OpenAI o1 模型,以及DeepSeek-v3等自家模型。而在上一轮DeepSeek-V3测试中所对照的Meta、Anthropic等公司模型,此时早已不见踪影。
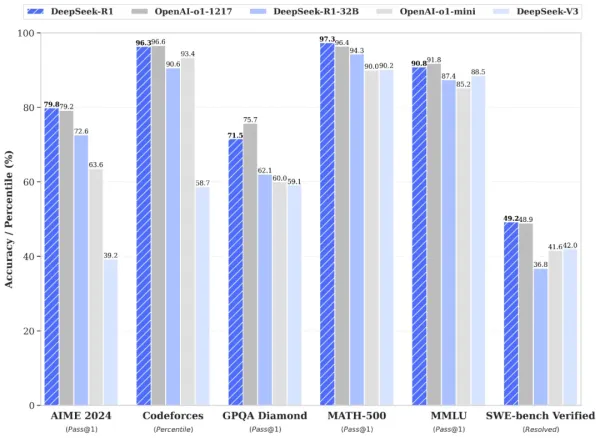
最重要的是,DeepSeek-V1以及深度求索同期提及的DeepSeek-V1-Zero模型,首次让整个行业清楚看到,大模型如何仅靠大规模强化学习(RL)驱动、在没有人类标注数据冷启动(SFT)的情况下,实现持续自我成长。简单说,DeepSeek-V1的意义就相当于让谷歌的围棋软件AlphaGo(阿法狗)从零开始自己与自己下棋,并通过试错自学达成如今的水平,但期间却不向AlphaGo提供任何人类大师的下棋思路信息。
而在成本方面,深度求索虽然未透露DeepSeek-V1 的训练花费,但DeepSeek-v3的总训练时长则为278.8万GPU小时(其中预训练占266.4万小时),使用2048块英伟达H800 GPU,耗时约两个月完成。与之相比,同样开源的Llama 3.1-405B却消耗了3080万GPU小时,成本是DeepSeek-V3的11倍。甚至OpenAI公司的 GPT-4o的模型训练成本也达到1亿美元,这与DeepSeek-V3训练花费的557万美元相差巨大,也让"花小钱办大事"成为深度求索的重要标签。
对此,在该Meta员工的帖子下边有一名三星员工评论称,特朗普日前宣布的"星球之门计划"预计投入总规模达到5000亿美元,"但如果当这些AI基础设施仅能与深度求索极小的成本相匹配时,投资人还能有多少耐心?这个5000亿美元的计划还没开始就将夭折。"

而谷歌公司的一名员工也评论称,深度求索很疯狂,不仅仅是Meta,面对这家中国公司时,OpenAI以及谷歌/Anthropic目前同样是"火烧屁股"。
不过这名谷歌员工也承认,对于行业来说是一件好事,"我们可以实时看到公开竞争对创新的推动作用"。