3月26日,一篇名为Dolphin -- 一款专为东方语言设计的语音大模型(Dolphin: A Large-Scale Automatic Speech Recognition Model for Eastern Languages)的论文在arXiv (康奈尔大学图书馆运营的一个开放获取的预印本平台)上发表。
目前,Dolphin 的base与small版模型与推理代码已经全面开源。
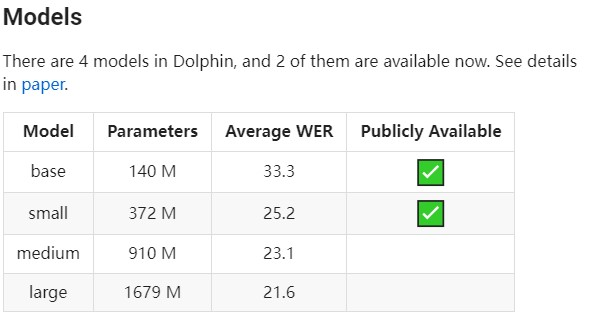
据悉,该项目来自海天瑞声和清华大学电子工程系语音与音频技术实验室的合作,两者共同推出了支持40个东方语种,以及22种中文方言(含普通话)的语音识别系统。
在数据方面,该系统的训练数据总时长21.2万小时,其中海天瑞声高质量专有数据13.8万小时,开源数据7.4万小时。
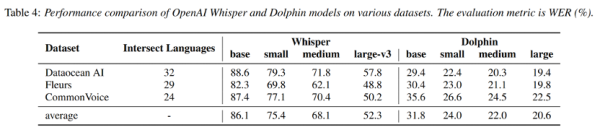
性能层面,通过与OpenAI推出的Whisper在同等尺寸模型的比较,根据参考三个多语言数据集(海天瑞声、Fleurs、CommonVoice)的平均值得出:
Dolphin base版模型的WER(词错率)为 31.8%,而 Whisper large-v3 版模型的词错率为 52.3%。从这个角度看,尽管dolphin基础版模型的规模不到 Whisper large-v3 版模型的十分之一,但在针对这些语言进行评估时,其词错率与 Whisper large-v3 模型相比相对降低了 39%,这凸显了dolphin的性能优势。
具体技术上,Dolphin网络结构基于CTC-Attention架构,E-Branchformer编码器和Transformer解码器,并引入了4倍下采样层。
CTC-Attention架构能够提升模型的识别准确性和效率;Branchformer编码器采用并行分支结构,能够更有效地捕捉输入语音信号的局部和全局依赖关系,为模型提供了更丰富的特征表示;Transformer解码器确保系统能够提供高质量的文本输出;4倍下采样层可以减少输入特征的序列长度,从而加速计算过程,同时保留关键的语音信息,确保模型的识别效果不受影响。
此外,Dolphin还引入了两级语种标签系统,第一个标签指定语种(例如<zh>、<ja>),第二个标签指定地区(例如<CN>、<JP>)。
这种分层方法使模型能够捕捉同一种语言内不同方言和口音之间的差异,以及同一地区内不同语言之间的相似性,从而提高了模型区分密切相关的方言的能力,并通过在语言和地区之间建立联系增强泛化能力。
海天瑞声表示,通过共享技术成果,希望能够吸引更多的开发者和研究机构参与到东方语言语音识别的研究中来,共同推动技术进步。